多种电商商品数据爬虫项目脚本
- 发表于
- 安全工具
ECommerceCrawlers
爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。本项目是一个针对多种电商商品数据爬虫。通过实战项目练习解决一般爬虫中遇到的问题。这是一个很好的例子减少重复收集轮子的过程。项目经常更新维护,确保即下即用,减少爬取的时间。
CrawlerDemo
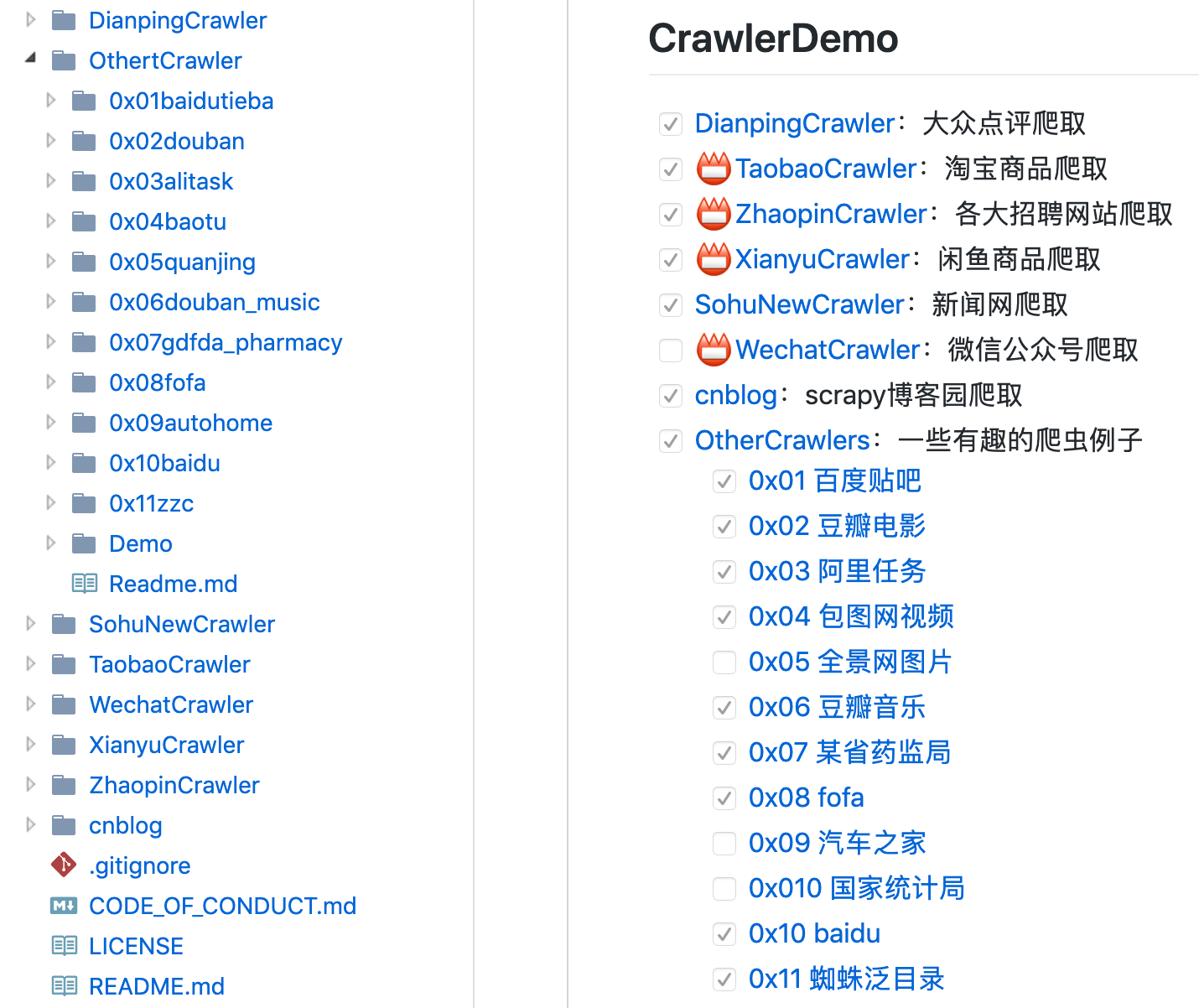
- DianpingCrawler:大众点评爬取
- TaobaoCrawler:淘宝商品爬取
- ZhaopinCrawler:各大招聘网站爬取
- XianyuCrawler:闲鱼商品爬取
- SohuNewCrawler:新闻网爬取
- WechatCrawler:微信公众号爬取
- cnblog:scrapy博客园爬取
- OtherCrawlers:一些有趣的爬虫例子
- 0x01 百度贴吧
- 0x02 豆瓣电影
- 0x03 阿里任务
- 0x04 包图网视频
- 0x05 全景网图片
- 0x06 豆瓣音乐
- 0x07 某省药监局
- 0x08 fofa
- 0x09 汽车之家
- 0x010 国家统计局
- 0x10 baidu
- 0x11 蜘蛛泛目录
本项目涉及的爬虫技术
本项目使用了哪些有用的技术
原文连接:多种电商商品数据爬虫项目脚本 所有媒体,可在保留署名、
原文连接
的情况下转载,若非则不得使用我方内容。